
Chcąc przetetestować jak działają bazy wektorowe i similarity search przygotowałem prosty eksperyment.
Krok 1. Qdrant
Jako bazę postanowiłem użyć rozwiązania opensource o nazwie qdrant. Instaluję go przez dockera. Plik docker-compose dostaje taki oto kontener:
qdrant:
image: qdrant/qdrant
environment:
- QDRANT__STORAGE__STORAGE_PATH=/var/lib/qdrant
volumes:
- qdrant_data:/var/lib/qdrant
ports:
- "6333:6333"
Po chwili qdrant jest gotowy do użycia:
Krok 2. Dane
Postanowiłem zaindeksować jedną ze stron centrum pomocy sklepu tim.pl: Rejestracja i Logowanie. Na razie nie chcę tracić czasu na konfigurację jakiegoś scrappera, czy parsera do markdown (co najprawdopodobniej będzie konieczne gdybym chciał indeksować więcej danych). Kopiuję więc treść, formatuję i markdown (dodając nagłówki i linki – obrazki pomijam dla ułatwienia).
Tak wygląda fragment tego pliku:
### Jak mogę zarejestrować się na TIM.pl? Aby zarejestrować się na TIM.pl, wejdź na poniższy link lub kliknij przycisk ["Zarejestruj się"](https://www.tim.pl/rejestracja) znajdujący się nad ikoną koszyka. Najpierw wybierz jakim klientem jesteś. Jeśli reprezentujesz firmę, powinieneś założyć konto biznesowe. Jeśli jesteś konsumentem, powinieneś założyć konto klienta detalicznego. Od wyboru konta zależy to, jakie funkcjonalności zostaną Ci udostępnione, oraz Twój indywidualny cennik. ### Jak założyć biznesowe / firmowe konto klienta? Aby założyć konto biznesowe, powinieneś podać adres e-mail oraz dane firmy: 1. Numer NIP firmy: nasz system jest połączony z systemami CEiDG oraz GUS. Jeśli w bazie jest NIP Twojej firmy, to przy rejestracji część danych zostanie uzupełniona automatycznie. 2. Dane siedziby firmy, imię i nazwisko, dane kontaktowe. [..]
Krok 3. Kolekcja
Zanim rozpocznę indeksację konieczne jest utworzenie kolekcji na wektory. W celu obsługi qdrant wykorzystuję paczkę hkulekci/qdrant.
W taki oto sposób tworzę kolekcję (jest to jedna z funkcji repozytorium, który tworzę do obsługi bazy). Istotna jest tutaj wielkość wektora, który musi być dokładnie taki jaki generować będzie model do embeddingu.
public function createCollection(string $collectionName, string $vectorName, $vectorSize = 1536): ?Response
{
$collection = $this->getCollection($collectionName);
if ($collection) {
return $collection;
}
$createCollection = new CreateCollection();
$createCollection->addVector(new VectorParams($vectorSize, VectorParams::DISTANCE_COSINE), $vectorName);
$this->qdrant->collections($collectionName)->create($createCollection);
return $this->getCollection($collectionName);
}
Krok 4. Indeksacja
W celu zaindeksowania powyższego pliku w bazie wektorowej mam następujący plan:
- Wczytać plik i podzielić go na fragmenty
- Wzbogacić fragmenty o metadane
- Wygenerować embedding dla fragmentu
- Wprowadzić wektor do bazy.
A tak wygląda implementacja tego planu:
// read file
$content = file_get_contents(__DIR__ . '/rejestracja.md');
$content = explode("\n\n", $content);
// create documents with metadata
$documents = array_map(function ($item) {
return [
'source' => 'help_center',
'page' => 'rejestracja',
'content' => $item,
'uuid' => crc32(uniqid()),
];
}, $content);
// generate points
$points = new PointsStruct();
foreach ($documents as $document) {
$embedding = $this->client->embeddings()->create(
[
"model" => "text-embedding-ada-002",
"encoding_format" => "float",
"input" => $document['content'],
]
)->embeddings[0]->embedding;
$points->addPoint(
new PointStruct(
$document['uuid'],
new VectorStruct($embedding, 'help_center_vector'),
$document
)
);
}
// insert points
$this->qdrantRepository->collectionUpsert('help_center', $points);
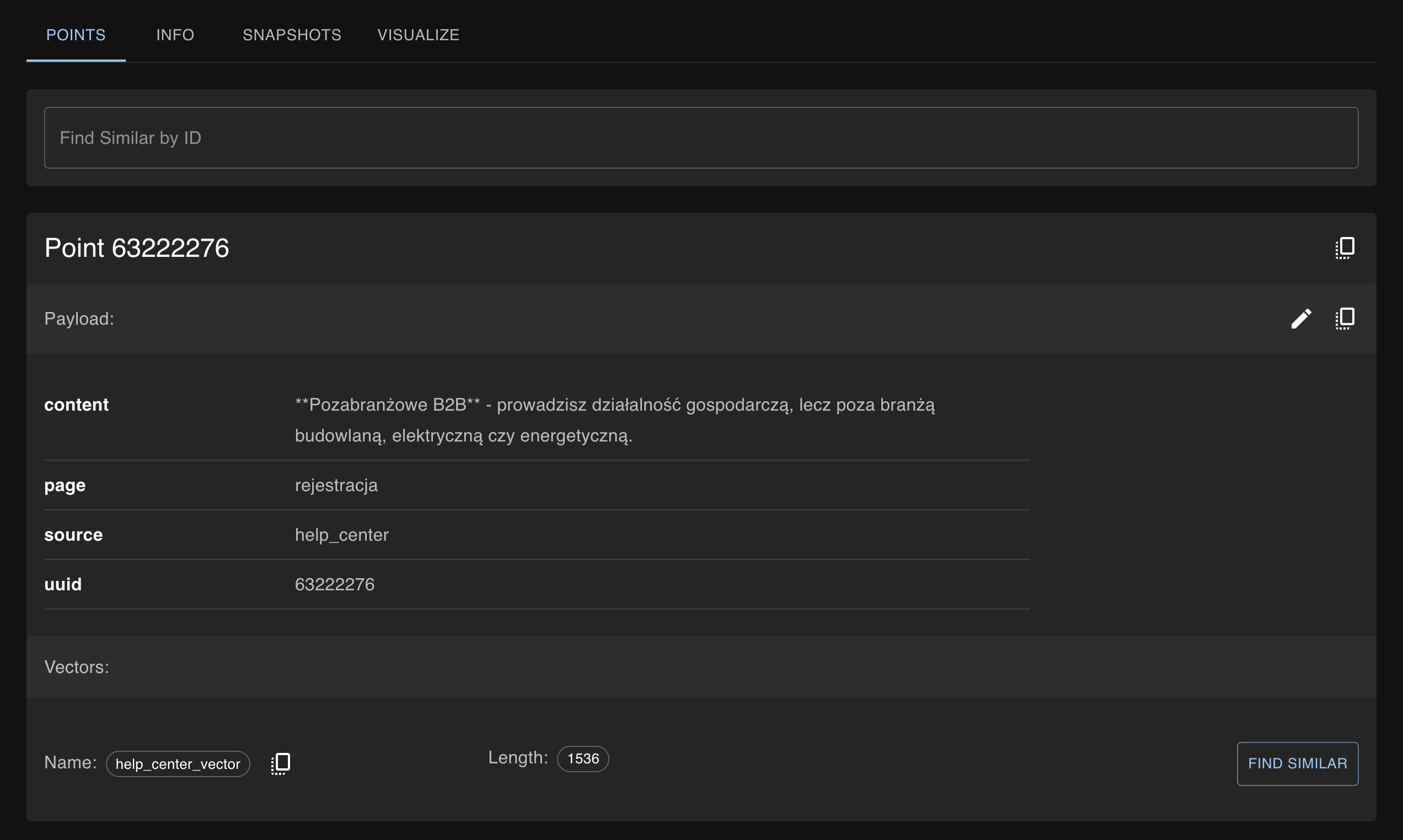
Tak wygląda efekt powyższego procesu:
Krok 5. Przeszukiwanie
Pozostało tylko umożliwić wyszukiwanie wektorów podobnych. Plan na tę operację jest następujący:
- Odebranie frazy / pytania od użytkownika
- Wygenerowanie embedingu dla zapytania użytkownika
- Przeszukanie bazy w kierunku podobieństw.
Przygotowałem dodatkową komendę umożliwiającą realizację powyższego scenariusza:
$questionHelper = $this->getHelper('question');
// Ask for search phrase
$question = new Question('Please enter search phrase: ');
$searchPhrase = $questionHelper->ask($input, $output, $question);
// Get embedding for search phrase
$embedding = $this->client->embeddings()->create(
[
"model" => "text-embedding-ada-002",
"encoding_format" => "float",
"input" => $searchPhrase,
]
);
// Search for similar documents
$searchResponse = $this->qdrantRepository->search(
"help_center",
$embedding->embeddings[0]->embedding,
3
);
dump($searchResponse->__toArray());
Krok 6. Profit?
Uruchomienie powyższej metody, daje naprawdę ciekawe rezultaty:
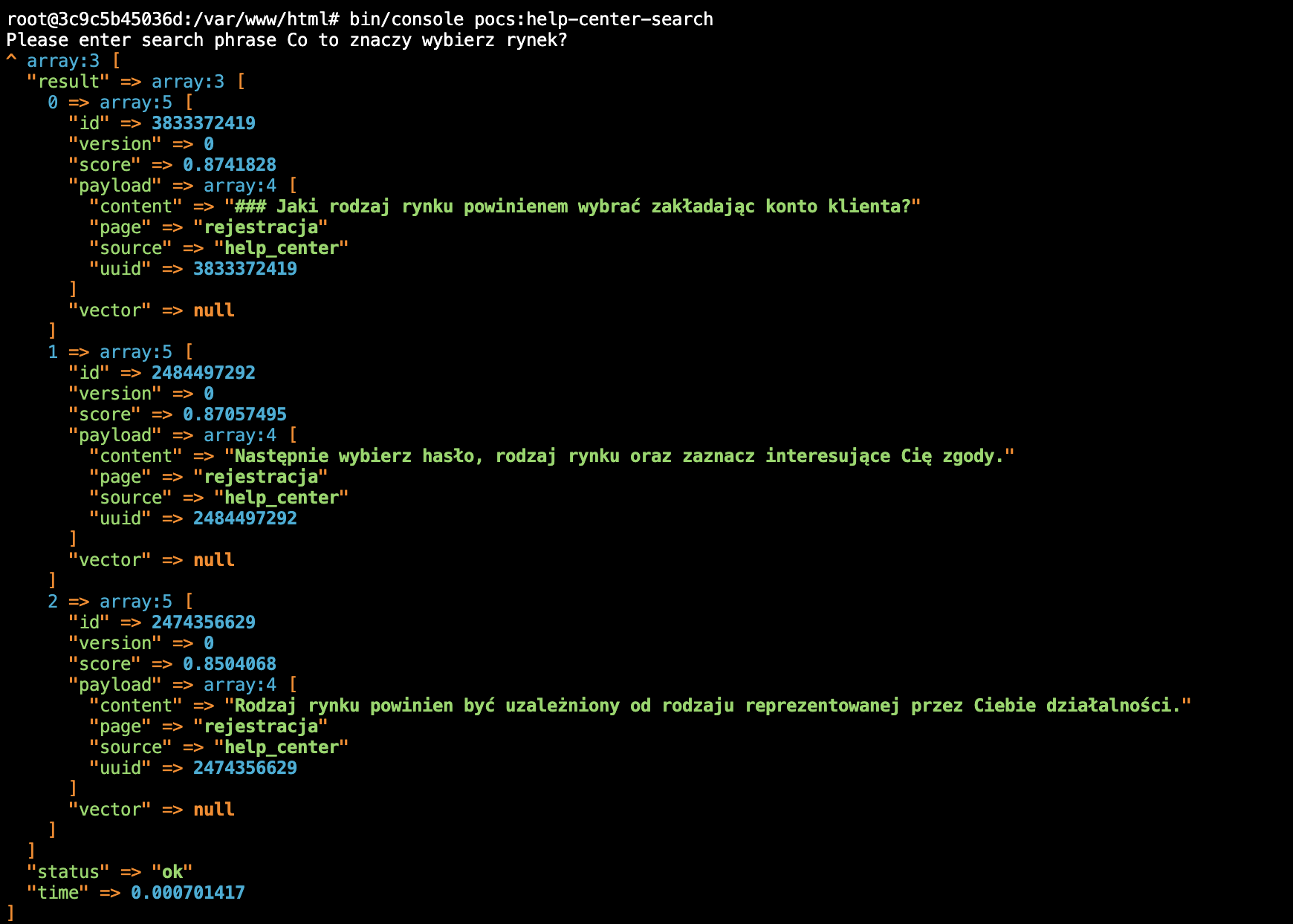
Co zawiera wynik? Przede wszystkim mamy określoną liczbę wektorów podobnych. Otrzymujemy scoring podobieństwa danego wektora. W tym przypadku otrzymaliśmy trzy najbardziej podobne wektory.
Dane otrzymane z bazy nie stanowią oczywiście bezpośredniej odpowiedzi dla użytkownika, więc w zasadzie co udało się osiągnąć?
Załóżmy, że w naszej bazie jest znacznie więcej danych (np wszystkie strony z działu Centrum pomocy lub nawet więcej). Ze względu na ograniczenia (i optymalizację kosztów) nie możemy ich wszystkich przekazać do modelu w celu przygotowania odpowiedzi na pytanie. Takie wyszukiwanie podobieństw w referencyjnej bazie może więc posłużyć jako zawężenie tej bazy do miejsc gdzie najprawdopodobniej znajduje się odpowiedź na zadane pytanie. Te fragmenty przekazujemy do modelu GPT, który posłuży się nimi w celu przygotowania spójnej odpowiedzi dla użytkownika. Znacząco zwiększa to prawdopodobieństwo, że dostarczona odpowiedź będzie wartościowa. Ale to następnym razem..