
Kontynuując poprzedni wpis o bazach wektorowych warto rozbudować nieco mechanizm SimilaritySearch, aby właściwie skorzystać z tej funkcji do zbudowania Proof of Concept konkretnego rozwiązania. Idea jest prosta. Dajmy możliwość zadania pytania (zamiast wyszukiwania), następnie wyszukajmy w bazie danych (za pomocą similarity search) podobnych fraz, które pomogą zbudować kontekst dla modelu. Dzięki temu kontekstowi powinno się udać osiągnąć rozwiązanie, w którym ogólny model wspiera proces w dość zamkniętej domenie, wspierany informacjami z bazy. Zaczynamy.
Krok 1. Refactor indeksera danych
Teoretycznie można by przejść od razu do sedna i na podstawie osiągnięć z poprzedniego wpisu zbudować kontekst dla modelu. Jednak dane otrzymane z wyszukiwania nie są do końca spójne. Otrzymujemy listę kilku podobnych wektorów wraz z ich scoringiem. Może się jednak okazać, że jest to za mało dla modelu. Bardzo łatwo o sytuację, gdy otrzymamy tylko część frazy (ze względu na jej podobieństwo), ale nie otrzymamy frazy np występującej zaraz po niej, w której były istotne informacje.
Aby tego uniknąć każdy wektor powinien mieć identyfikator, dzięki któremu możemy wyciągnąć oryginalną treść lub jej fragment. W moim przypadku jestem jeszcze na dość uproszczonym momencie i dane wejściowe przygotowywałem w zasadzie ręcznie. Zamiast budować zewnętrzne źródło danych do których będę sięgał, postanowiłem na razie ograniczyć się do otagowania w metadanych wektora informacji o rozdziale z którego pochodzi dany wektor. Po wyszukaniu wektora /ów podobnych zaciągnę wszystkie wektory z danego rozdziały i to one będą stanowić kontekst. W docelowym rozwiązaniu niemal na pewno będzie to wymagało zmiany, ale na potrzeby POC powinno wystarczyć.
Przy okazji zmian usprawniam nieco kod z poprzedniego wpisu i dodaję dzielenie na rozdziały i wprowadzam tytuł rozdziału do metadanych.
Główna metoda wygląda teraz bardzo prosto:
$content = file_get_contents(__DIR__ . '/rejestracja.md');
$chapters = explode("\n### ", $content);
foreach ($chapters as $chapter) {
$this->indexChapter($chapter);
}
Metoda indexChapter zajmuje się budowaniem metadanych oraz podzieleniem rozdziału na poszczególne linie:
private function indexChapter(string $chapter): void
{
$lines = explode("\n", $chapter);
$title = $lines[0];
$metadata = [
'source' => 'help_center',
'page' => 'rejestracja',
'chapter' => $title,
];
$points = new PointsStruct();
foreach ($lines as $line) {
if ($line === "") {
continue;
}
$points->addPoint(
$this->indexLine($line, $metadata)
);
}
// insert points
$this->qdrantRepository->collectionUpsert('help_center', $points);
}
Ostatnim krokiem jest wygenerowanie embeddingu lini i wygenerowanie odpowiedniego wektora:
private function indexLine(string $line, array $metadata): PointStruct
{
$embedding = $this->client->embeddings()->create(
[
"model" => "text-embedding-ada-002",
"encoding_format" => "float",
"input" => $line,
]
)->embeddings[0]->embedding;
$metadata['line'] = $line;
$metadata['uuid'] = Uuid::uuid4()->toString();
return new PointStruct(
$metadata['uuid'],
new VectorStruct($embedding, 'help_center_vector'),
$metadata
);
}
Krok 2. Budowa kontekstu
Po przeindeksowaniu danych ponownie upewniam się, że wyszukiwanie działa prawidłowo:
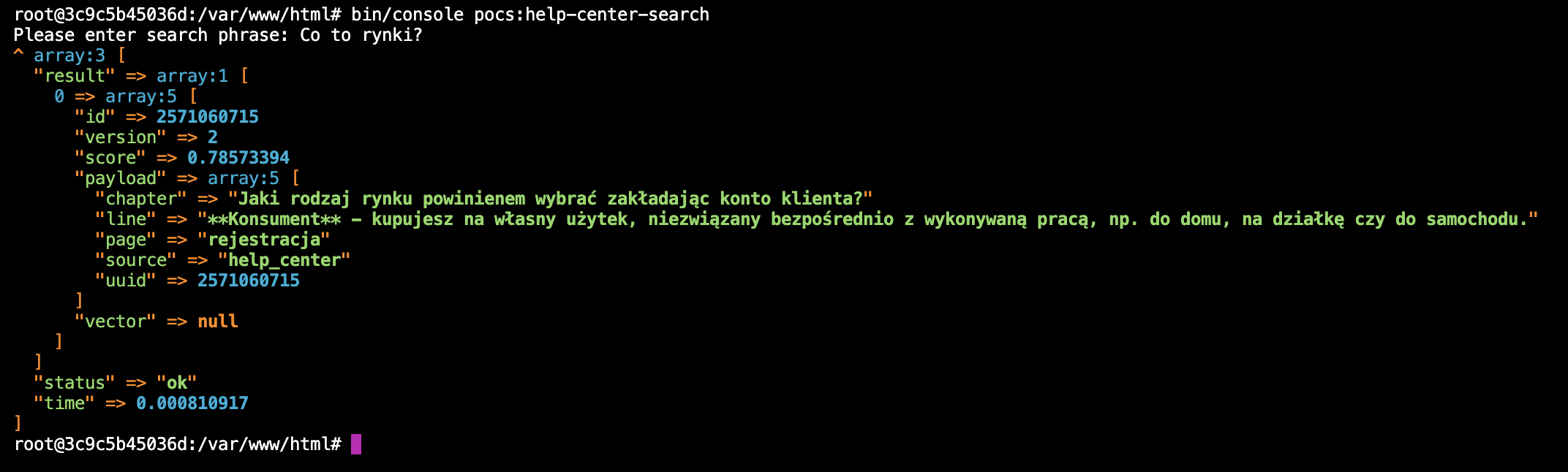
Wszystko działa jak należy. Widać tutaj różnicę względem poprzedniej wersji, a jest nią parametr chapter w metadanych wektora. Wykorzystajmy ten parametr, aby załadować cały rozdział.
Do repozytorium Qdranta, które tworzę, dopisuję sobie metodę do pobierania punktów na podstawie jednego taga z metadanych
public function scroll(string $collectionName, string $vectorName, string $metadataKey, string $metadataValue): Response
{
$filter = new Filter();
$filter->addMust(
new MatchString(
$metadataKey,
$metadataValue
)
);
return $this->qdrant->collections($collectionName)->points()->scroll(
$filter,
[
'with_payload' => false,
'limit' => 1000,
]
);
}
Wobec tego wynik wyszukiwania podobieństwa, zrealizowany w poprzednim wpisie, wykorzystuję do pobrania wszystkich linii z danego rozdziału:
$chapter = $searchResponseArray['result'][0]['payload']['chapter'];
// Load all lines from chapter
$scrollResponse = $this->qdrantRepository->scroll(
'help_center',
'help_center_vector',
'chapter',
$chapter,
);
$scrollResponseArray = $scrollResponse->__toArray();
$chapterLines = array_map(
function ($item) use ($chapter) {
return $item['payload']['line'] !== $chapter ? $item['payload']['line'] : null;
},
$scrollResponseArray['result']['points']
);
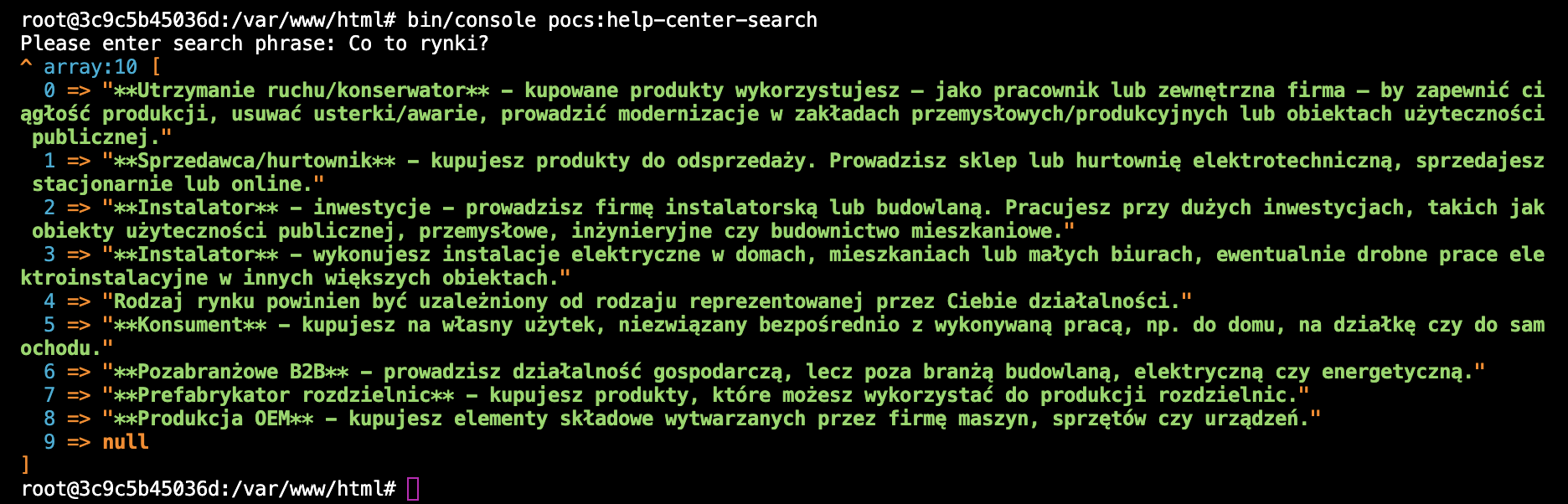
dump($chapterLines);
A oto efekt działania searcha. W celu choć minimalnej optymalizacji kosztów linia z tytułem rozdziału została usunięta (null w ostatnim elemencie tablicy). Tytuły raczej nie wnoszą nic co mogło by pomóc modelowi w przygotowaniu odpowiedzi.
Krok 3. Generowanie odpowiedzi
Pozostało już tylko jedno. Mając zestaw danych wejściowych przygotujmy zapytanie do modelu GPT, aby odpowiedział na pytanie zadane przez użytkownika.
private function answerQuestion(string $question, array $context): string
{
$context = json_encode($context);
$prompt = [
// 'model' => 'gpt-3.5-turbo-1106',
'model' => 'gpt-4-1106-preview',
'messages' => [
[
'role' => 'system',
'content' => <<<EOT
Odpowiedz na pytanie użytkownika tak prawdziwie jak potrafisz używając tylko i wyłącznie kontekstu poniżej.
Jeśli nie znasz odpowiedzi, zwróć `Nie wiem`.
Context:
###
$context
###
EOT
],
[
'role' => 'user',
'content' => $question
],
],
'max_tokens' => 400,
];
$response = $this->client->chat()->create($prompt);
return $response->choices[0]->message->content;
}
Odpowiedź testowałem stosując różne modele. Braki w kontekście i niedoskonałości prompta można skutecznie zamaskować stosując mocniejszy model. Oczywiście jest to połączone z wolniejszym działaniem i wyższymi kosztami.
Tak wygląda odpowiedź wygenerowana przez GPT-3.5-turbo-1105

Tak natomiast prezentuje się GPT-4-1106-preview
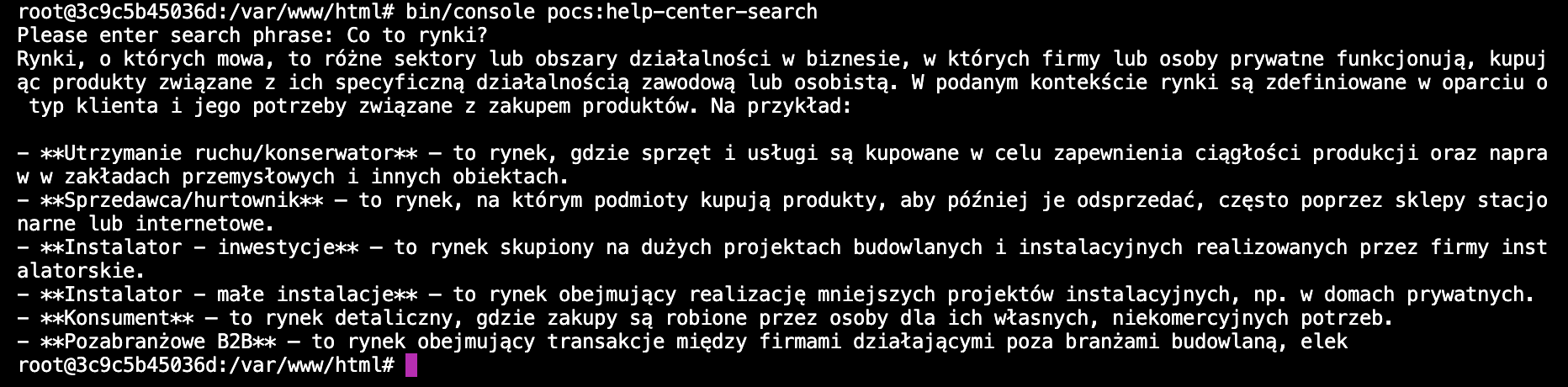
Obie te odpowiedzi powinny zostać uzupełnione o link do źródła. Z powyższego przykładu widać, że na początkowym etapie projektu warto wybierać mocniejszy model, aby później w ramach prac optymalizacyjnych dopracować aplikację i móc zejść na słabszy (ale szybszy i tańszy) model 3.5.